
The Obama Marionette: Artificial Intelligence Meets Fake News in a Frightening Video from the Future
Photo by Alex Wong

A research team from the University of Washington has used artificial intelligence technology to make what you could call a “fake news” video of Barack Obama giving a speech he didn’t give.
Yeah.
The team didn’t exactly write the speech themselves, though it’s reasonable to think they could have. Instead, they took audio clips from a variety of real Obama speeches and dropped them into video of a single Oval Office address. This isn’t like those always enjoyable Bad Lip Reading videos, where you have video in search of different words that will fit it. No: the researchers altered the actual video of the Oval Office address so that Obama looked like he was saying things they wanted him to say.
Yeah.
In order to “train” Videobama to speak like real Obama, the researchers fed hours and hours of video of Obama speaking to a neural network until it learned how to mimic his mouth, face, and head when any word was dropped in from a separate audio source. You could call it virtual ventriloquism: the Obama on the screen is a virtual puppet that will automatically lip-sync whatever words you put in its mouth. Presidentriloquism. If you didn’t know this was faked and weren’t even thinking about the possibility, it would be unlikely this video would give you pause, especially if you were watching casually, in passing. Keep in mind, too, that although this technology is in its infancy, Moore’s law explains that, generally speaking, computational power doubles roughly every two years. So look the fuck out. Also, this is already pretty damn convincing.
This is the stuff of hologram dreams, where sci-fi becomes sci-non-fi.
But it’s a propaganda nightmare.
The Good
The technology involved is dazzling. Here’s the full paper. And because I worked in a misunderstood and widely despised tech sector for a few years, I feel obligated to hit the positives before leaping to the dystopian stuff. Such a leap, though, seems merited.
First, in pragmatic terms, the ability to generate video directly from audio clips could, according to the researchers, greatly reduce bandwidth needed for video en/decoding and transmission, which uses a great deal of the world’s Internet bandwidth. For instance, something like 300 hours of video are uploaded to YouTube every minute, which is five hours of video a second. On the receiving end of the bandwidth equation, more than half of YouTube views are on mobile devices.
For the hearing-impaired, this technology could generate video from audio clips such as phone calls or voice messages, which could then be used for long-distance lip-reading. And of course there are the endless entertainment applications, such as for special effects, video editing, video games, and next-level trolling. The researchers ultimately want to be able to apply the technique to all sorts of online video, such as speeches, movies, or even Skype calls.
The Tech
Lots of highly advanced computation technology is involved here, including neural networks and optical flow. In broad strokes, though, the program (for lack of a better term) converts audio input to a moving mouth shape, which is blended into Obama’s face. His face, jawline, and head also move in sync to the new words. It’s really a lot like puppetry.
Right now, of course, it’s very hard to do. I mean, this is one of the first, if not the first, projects of its kind to meet with this kind of success. And though you might not think so, it’s actually pretty tough to train an AI program to synthesize lifelike teeth and mouth shapes from millions of video frames, then seamlessly integrate and synchronize those composite shapes (and movement sequences) into the shapes and movements of real faces and heads, and, finally, sync the whole thing to audio clips with millisecond intervals between phoneme tags.
Teeth, it turns out, are surprisingly hard to synthesize. Less surprisingly, so is emotion.
Also, it doesn’t help that we’re highly tuned, biologically, to reading subtle inflections around the mouth. The virtual mouth could easily fall into the uncanny valley. We’ve been on the lookout for this for a while, it seems, which, I’m sad to say, is soon going to be put to the test.
Artificial Intelligence, Meet Fake News
We’ve already passed an inflection point in the history of information: the 2016 election and its hordes of bots, memes, misinformation, hacks, and fake news has transformed for good the way we consume information. The truth in America will never be the same, if it ever was, and there’s no going back. This is also possibly an inflection point for the collapse of democracy or something even deeper and more troubling, but I’ll refer you to other articles in this series for that: here; and here.
First, the researchers chose Obama for a practical reason: they needed as much video of their chosen model as possible, and President Obama is, in terms of video, one of the most well documented people of all time.
But there’s a side effect: the video political subtext is clear. The mind jumps straight to the propaganda power of pictures: seeing is believing.
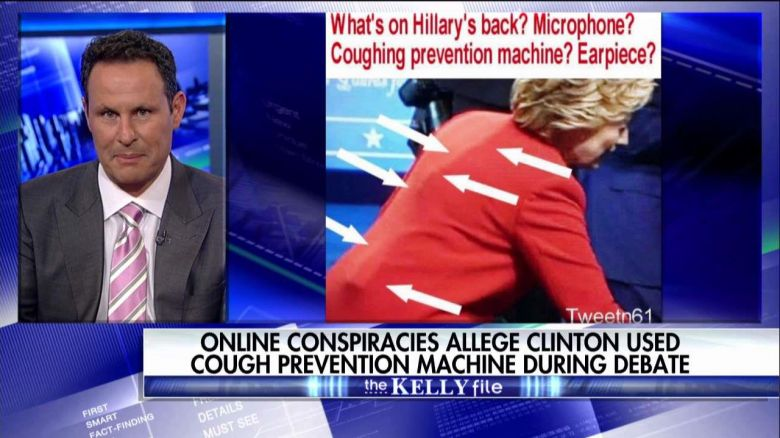
A lot of people (really) believed this was in fact a coughing prevention machine, which was in keeping with a flood of theories about her health, embraced and promotedthroughout the campaign by none other than Donald Trump himself. Now imagine if this were accompanied by a seemingly recent video of what looks to all the world like Clinton talking about how worried she was about her “illness.”
{kind=link}
The bar for pulling off believable candid video is much lower than for still photos like the one above. Remember the video of Mitt Romney’s 47% gaffe? That was the real deal, and the video and audio quality are terrible. Or consider the broad range of ambiguity—and “ambiguity”—of police dashcam or body cam footage.
Imagine the mind- and culture-warping effect of pumping out hours of fraudulent propaganda video. Or, even worse, misleading information via video. After all, we already know that small edits can make outsized impressions. See, for instance, the persuasive power that deceptive editing tricks have over people today. The malignant douchebags over at Project Veritas dropped more than a few faked tapes during the election. And then there’s the case of David Daleiden, whose ersatz edits of Planned Parenthood employees selling fetal tissue for profit made it all the way to Capitol Hill before they were nationally debunked. This earned him felony charges, but he still has support from his true believers. Most recently, Project Veritas put out a faked hit job on Van Jones, taking his remarks about CNN’s coverage of the Russia investigation out of context.
These are objectively bad people. They target the casual observer who either doesn’t know what to look for, doesn’t have the capacity to tell between what’s real and what’s fake, doesn’t care, or, worst of all, doesn’t want to be wrong. This technology will make it much worse. Don’t doubt for a second that computer science genius, fake newsie, and Google gamer Robert Mercer isn’t all over this.
The thing is, it doesn’t take much to make an indestructible impression in the mind of a viewer, especially a viewer predisposed to seeing what she’s looking for. The information war is asymmetric: a little money and a little effort make a huge difference. Russia spent an estimated $200 million (million!) in its effort to sway the 2016 election with misinformation. By comparison, the campaigns themselves spent a combined $6.8 billion.
How does that work?
The Other
Propaganda (fake news) has built-in multipliers thanks to the reach and speed of the internet, mobile connectivity, and social media, an effect further multiplied and complicated by the related hyperactive news cycle. This is basically built-in chaos. All it takes is someone to throw an armful of newspapers into this whirlwind, and there’s no predicting it, nor containing it.
Now compound this with cheap, powerful, and widely available graphics technology that allows virtually anyone to professionally doctor a photo or create a convincingly slick website or blog. Couple that with SEO know-how, cheap bot armies to serve as vectors of misinformation, and a willing, even rabid audience of true believers, and you can see how quickly the scales tip back to favor industrious and clever individuals.
We know about big brother, but we might have to worry even more about little brother.
Consider also that the vast majority of people (casual observers) can’t at first glance tell a good Photoshop job from something untouched. Most people can’t even tell a bad edit job at all until you tell them something’s wrong with the picture. And the properties of video, with its verisimilitude and mercurial nature—never still—lend it credibility and a degree of immunity from scrutiny that still photos will never have.
Not all is lost, though. We evolve in response to our technology. Our eyes learn, slowly but surely, what to look for. Think of how bad special effects look from old movies. Even movies from the ‘80s and ‘90s. Horrible, some of it. Our minds learn, too, slowly but surely, how to be more critical. In response to 2016, our society is becoming, for better or worse, slightly more shrewd and slightly more cynical consumers of information.
But here: compare these two rows of stills taken from the Obama videos. I pulled them directly from the research paper linked above. Tell me which is Obama and which is Videobama.


I’m not going to tell you the answer, because that’s not how this works in the real world. You’ve got to put your research in and make up your own mind. Here’s a hint, though: you’re probably wrong.
Or are you? By the way, how long did you spend comparing them, then researching them, if you researched at all?
This is the downside. I’m not sure the evolution of our senses of perception, aesthetics, and criticism will be enough. We certainly won’t keep up with Moore’s law. And if you really want to push the outlook, imagine what this means for AI generally: if neural networks can now synthesize human speech, and the technology is doubling every two years, it won’t be long before it catches up with humans. At least, it will catch up with us in specific areas. And which areas are we pouring research into? Well, information and media technology is right up at the top.
And then two years after it catches up with us, it’ll double again.
Here’s the problem for us: no matter what kind of evidence we’re presented with, no matter what quality or how much of it, nothing dictates or guarantees belief. Belief is fundamentally an individual choice. Do you believe your eyes, ears, and brain, or not? More importantly: do you believe other people? Why or why not? That’s my chief concern: as our societies continue our self-propelling, self-fulfilling fracturing into warring tribes, our beliefs about facts are increasingly turning to questions about how we identify ourselves, whom we identify with, and how we distinguish ourselves from the Other. This has consequences even more profound than a physical war. In war, the two sides reconcile with the winner subjugating the loser. A war of information isn’t about domination: It’s about distance. Reconciliation itself is the enemy.
Virtually Over
It was easy for the researchers to train their systems using a celebrity on the scale of Obama, but it’d be much more challenging to scale it down to mimic video of someone more private, who doesn’t have much video data available. But the researchers note this:
The relationship between mouth shapes and speaking “might well be, to some extent, speaker-independent. Perhaps a network trained on Obama could be retrained for another person with much less additional training data. Going a step further, perhaps a single universal network could be trained from videos of many different people, and then conditioned on individual speakers, e.g., by giving it a small video sample of the new person, to produce accurate mouth shapes for that person. While we synthesize only the region around the mouth and borrow the rest of Obama from a target video, a more flexible system would synthesize more of Obama’s face and body, and perhaps the background as well. Such a system could enable generating arbitrary length sequences, with much more control of how he moves and acts.” Emphasis mine.
In other words, big data could possibly be tapped to create a universally adaptive human mimicking program for almost any earthly environment. There’s a reason Google keeps all the rights to all the data for all its YouTube videos.
If you’re anything like me, this terrifies you. I think that’s a healthy reaction, especially given the times we’re now (suddenly) in. But I want to caution that any technology is agnostic. Moore’s law would apply to technology that can decipher the real from the fake. Perhaps information giants such as Google and Facebook can create AI to combat fake videos. But wouldn’t it be difficult to tell fake video, if rendered obscurely enough, from video that’s simply bad or poorly synced?
Tech leaders are fond of spewing the old bromide that the function of any technology is and has always been up to the user: You can use a hammer to hit someone on the head, or you can use it to help build someone a house. But this cliche, like so much arrogant, solipsistic bullshit that comes out of Silicon Valley, ignores the other end: it makes a hell of a difference to people who aren’t hammer users, but on the receiving end of that hammer’s gifts. We don’t have much choice when it comes to other people’s choices.
Thanks, Obama.